|
Drake
|


|
Drake
|
Drake System objects are used to specify the computational structure of a model to be studied. The actual values during computation are stored in a separate Context object. The Context contains source values (time, parameters, states, input ports, accuracy) and computed values (e.g. derivatives, output ports) that depend on some or all of the source values. We call the particular dependencies of a computed value its prerequisites. The caching system described here manages computed values so that
Accessing computed values is a critical, inner-loop activity during simulation (many times per step) so the implementation is designed to provide validity-checked access at minimal computational cost. Marking computations out of date as prerequisites change is also frequent (at least once per step), and potentially expensive, so must be efficient; the implementation goes to great lengths to minimize the cost of that operation.
Caching is enabled by default in Drake. Methods are provided for disabling and otherwise manipulating cache entries. See ContextBase for more information.
Caching is entirely about performance. Hence, other than correctness, the performance goals listed above are the primary architectural constraints. Other goals also influenced the design. Here are the main goals in roughly descending order of importance.
In service of correctness and speed we need instrumentation for debugging and performance measurement. For example, it should be possible to disable caching to verify that the results don't change.
Not a goal for the initial implementation: automatic determination or validation of dependency lists. Instead we rely on a conservative default (depends on everything), and the ability to disable caching during testing. Several follow-ons are possible to improve this:
This is the basic architecture Drake uses to address the above design goals.
Every declared source and computed value is assigned a small-integer DependencyTicket ("ticket") by the System (unique within a subsystem). The Context contains corresponding DependencyTracker ("tracker") objects that manage that value's downstream dependents and upstream prerequisites; these can be accessed efficiently using the ticket. Cached computations are declared and accessed through System-owned CacheEntry objects; their values are stored in Context-owned CacheEntryValue objects whose validity with respect to source values is tracked via their associated dependency trackers. Computed values may in turn serve as source values for further computations. A change to a source value invalidates any computed values that depend on it, recursively. Such changes are initiated via Context methods that send "out of date" notifications to all downstream dependency trackers, which set the "out of date" flag on cache entry values.
Any value contained in a Context may be exported via an output port that exposes that value to downstream Systems; inter-subsystem dependencies are tracked using the same mechanism as intra-subsystem dependencies. The current implementation assigns a cache entry to each output port and requires copying Context values to that cache entry in order to expose them. This may be improved later to allow values to be exposed directly without the intermediate cache entry, but the semantics will be unchanged.
From a user perspective:
Figure 1 below illustrates the computational structure of a Drake LeafSystem, paired with its LeafContext. A Drake Diagram interconnects subsystems like these by connecting output ports of subsystems to input ports of other subsystems, and aggregates results such as derivative calculations. When referring to individual Systems within a diagram, we use the terms "subsystem" and "subcontext".
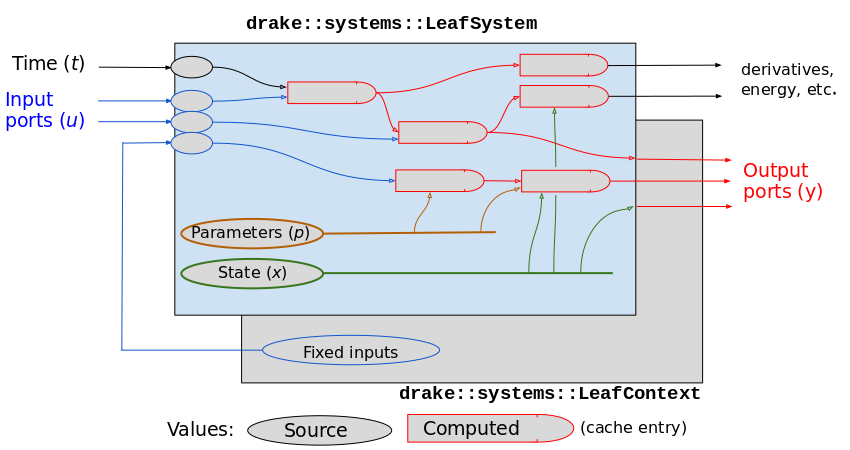
In Figure 1 above, values are shown in gray like the Context to emphasize that they are actually being stored in the Context. The System can declare the structure (colored borders), but does not contain the actual values. There can also be values in the Context of which the System is unaware, including the Fixed Input values as shown, and additional cached computations. Computed values depend on source values, but are shown rounded on one side to emphasize that they then become sources to downstream computations. The arrows as drawn should be considered "is-prerequisite-of" edges; drawn in the reverse direction they could be labeled "depends-on" edges.
When a cache entry is allocated, a list of prerequisite value sources is provided by listing the dependency tickets for those sources. Only intra-System dependencies are permitted; inter-System dependencies are expressed by listing an input port as a prerequisite. There are six kinds of value sources within a System's Context that can serve as prerequisites for cached results within that Context:
In addition, we support "fixed" input ports whose values are provided locally; each such value is a value source, but is restricted to its corresponding input port. Fixed values are semantically like additional Parameters.
The Accuracy setting serves as a prerequisite for cached computations that are computed approximately, to make sure they get recomputed if accuracy requirements change. That is a technical detail not of interest to most users. Its dependencies are handled similarly to time dependencies.
Each value source has a unique DependencyTicket that is used to locate its DependencyTracker in the Context. Further granularity is provided for individual value sources from the above categories. For example, configuration variables q and velocity variables v have separate tickets. The ticket is used to designate that source as a prerequisite for a cache entry. Tickets are assigned during System construction, whenever a component is specified that can serve as a value source. Each value source's DependencyTracker maintains a list of its dependents (called "subscribers") so that it can perform "out of date" notifications at run time, and is registered with its prerequisites so that it can be properly notified when it may be invalid.
An Output Port for a System is a "window" onto one of the value sources within that System's Context; that is the only way in which internal values of a System are exported to other Systems in a Diagram. That value source may be
An output port is a subscriber to its source, and a prerequisite to the downstream input ports that it drives.
Every output port has an associated dependency ticket and tracker. If there is a cache entry associated with the output port, it has its own ticket and tracker to which the output port's tracker subscribes. A Diagram output port that is exported from a contained subsystem still has its own tracker and subscribes to the source output port's tracker.
The value source for a subsystem input port is either
When an input port's value comes from a locally-stored value, we call it a fixed input port. Note that the fixed value is stored as a source value in the Context. There is no corresponding entry in the System since providing values for input ports is done exclusively via the Context (see Figure 1 above).
Fixed input ports are treated identically to Parameters – they may have numerical or abstract value types; they may be changed with downstream invalidation handled automatically; and their values do not change during a time-advancing simulation. The values for fixed input ports are represented by FixedInputPortValue objects, which have their own ticket and tracker to which the corresponding input port subscribes.
Every input port has an associated dependency ticket and tracker. The tracker is automatically subscribed to the input port's source's tracker.
Certain computations are defined by the system framework so are automatically assigned cache entries in the Context. Currently those are:
Output ports that have their own Calc() methods are also automatically assigned cache entries. Currently that applies to every leaf output port, but not to diagram output ports.
The API for declaring a cache entry is similar to the existing output port API. A cache entry is defined by an Allocator() method returning an AbstractValue, and a Calculator() method that takes a const (sub)Context and an AbstractValue object of the type returned by the Allocator, and computes the correct value given the Context, and a list of prerequisites for the Calculator() function, which are DependencyTickets for value sources in the same subcontext.
In the absence of explicit prerequisites, a cache entry is implicitly presumed to be dependent on all possible values sources, so will be marked "out of date" whenever accuracy, time, any input port, parameter, or state variable may have a changed value. However, no implicit dependency on other cache entries is assumed.
A typical declaration looks like this (in the constructor for a LeafSystem):
That is a templatized "sugar" method where the allocator has been specified to simply copy the given default value. The usual variants are available, as for output port declarations. See Declare cache entries in SystemBase for the full collection of variants.
If no dependencies are listed in a cache entry declaration, the default is {all_sources_ticket()}. A cache entry that is truly independent of all sources must explicitly say so by specifying {nothing_ticket()}. The available tickets are defined in the SystemBase class; see Dependency tickets there. Once declared, the new CacheEntry object's CacheIndex and DependencyTicket can be obtained from the entry if needed.
The following dependency tickets are always available and are used to select particular built-in dependency trackers. During System construction, an API user can obtain the ticket number as the return value of methods like time_ticket() that are provided by SystemBase. Add _ticket() to the names in the first column of the table below to obtain the name of the method to use in a prerequisite list as shown in the previous section. Ticket methods followed by (i) in the table below are assigned as the indicated resource is allocated; they do not have pre-assigned ticket numbers.
| Ticket name | Abbr | Prerequisite indicated | Subscribes to |
|---|---|---|---|
| nothing | has no prerequisite | — | |
| time | t | simulated time | — |
| accuracy | a | accuracy setting | — |
| q | continuous configuration | — ¹ | |
| v | continuous velocity | — ¹ | |
| z | misc. continuous state | — ¹ | |
| xc | any continuous state | q v z | |
| xd | any discrete state | xdᵢ ∀i ¹ ² | |
| xa | any abstract state | xaᵢ ∀i ¹ ² | |
| all_state | x | any state variable | xc xd xa |
| pn | any numeric parameter | pnᵢ ∀i ¹ ² | |
| pa | any abstract parameter | paᵢ ∀i ¹ ² | |
| all_parameters | p | any parameter p | pn pa |
| all_input_ports | u | any input port u | uᵢ ∀i |
| all_sources | any change to Context | t, a, x, p, u | |
| configuration | may affect pose or PE | q, z, a, p, xd, xa ³ | |
| kinematics | may affect pose/motion | configuration, v ³ | |
| xcdot | d/dt xc cached value | all_sources ¹ ⁵ | |
| pe | potential energy | all_sources ¹ ⁵ | |
| ke | kinetic energy | all_sources ¹ ⁵ | |
| pc | conservative power | all_sources ¹ ⁵ | |
| pnc | non-conservative power | all_sources ¹ ⁵ | |
| numeric_parameter(i) | pnᵢ | one numeric parameter | — ² |
| abstract_parameter(i) | paᵢ | one abstract parameter | — ² |
| discrete_state(i) | xdᵢ | one discrete state group | — ² |
| abstract_state(i) | xaᵢ | one abstract state | — ² |
| input_port(i) | uᵢ | one input port | peer, parent, or self ⁴ |
| cache_entry(i) | cᵢ | one cache entry | explicit prerequisites |
Notes
v state variables or which parameters may affect kinematics, so we have to depend on all of them. However, we do not propagate downstream notifications from state variable trackers if a LeafContext does not have any of those state variables (see next section for more information).Fixed input port values and output ports also have associated trackers. There are methods for obtaining their tickets also but they are for internal use. Only input ports may subscribe to those trackers, and that is handled by the framework when the source for an input port is established.
In the above table, entries that don't subscribe to anything ("—") are primary source objects. For example, q is an independent state variable so its tracker doesn't depend on anything else. Trackers like xc are composites, meaning they are shorthand for a group of independent objects. xc is a tracker that subscribes to the trackers for q, v, and z. Similarly xd stands for all discrete state variables, and subscribes to each of the individual discrete state trackers. That way if a q is modified, xc gets notified automatically. Similarly a change to a single discrete state variable notifies xd. Once those subscriptions are set up, no additional code is required in Drake to propagate the notifications. As an optimization, we do not propagate notifications from a state variable source tracker (q, v, z, xd, xa) in LeafContexts that do not have any of that particular kind of state variable – see issue #21133 for why this is an important optimization.
Let's call the above the "forward" direction,where a source entity notifies a subscribing composite entity. More subtly, we also have to issue notifications in the "backward" direction. That's because the Context provides methods like SetContinuousState() and get_mutable_state() which effectively change a group of source objects. That could be handled with more subscriptions, at the cost of introducing cycles into the dependency DAG (the "change event" would serve to break those cycles during notification sweeps). Instead, since we always know the constituents at the time a high-level modification request is made, we simply have bespoke code that notifies the lowest-level constituents, then depend on the "forward" direction subscriptions to get the composite trackers notified. See the notifications methods in ContextBase.
There are additional considerations for Diagram notifications; those are discussed in the next section.
Diagrams have some implementation details that don't apply to leaf systems. Diagrams do not have their own state variables and parameters. Instead, their states and parameters are references to their child subsystems' corresponding states and parameters. This applies individually to each state and parameter category. Diagram contexts do have trackers for their composite state and parameters, and we must subscribe those to the corresponding child subsystem trackers to ensure notifications propagate upward. Using capital letters to denote the Diagram composite trackers we have:
where 𝕊 is the set of immediate child subsystems of a Diagram. Note that the higher-level built-in trackers (all_state, all_parameters, configuration, etc.) do not require special treatment. They simply subscribe to some or all of the diagram source trackers listed above. They may also subscribe to time, accuracy, and diagram-level input ports, none of which have dependencies on child subsystems.
In addition to composite sources, Diagrams have a limited set of built-in computations that are composites of their children's corresponding computations. These are
Each of these has a cache entry and an associated Calc() method that sets the cache value by visiting the children to Eval() the corresponding quantities, which are then combined to produce the composite quantity. xcdot is just a container for the collected child quantities so just needs to ensure these are up to date. Energy and power are scalars formed by summing the corresponding scalar quantities from each child subsystem. To ensure that the diagram cache entries are updated appropriately, they subscribe to the corresponding child cache entries' dependency trackers. That way if a leaf quantity gets notified of a leaf context change, any composite diagram quantity that needs that leaf quantity is automatically notified also.
Modifications to state variables and parameters are always initiated through one of the mutable methods of the Context class, but not necessarily at the root DiagramContext of a Context tree. Wherever a modification is initiated, we must propagate that change in both directions: down to the child subsystems, and up to the parent diagram. If someone changes the root diagram Q, that is a change to each of its constituents qₛ, so we need to notify "down" to the trackers for each of those, to make sure that subsystem s computations that depend on qₛ will be properly marked "out of date". In the "up" direction, a user who has access to one of the child subcontexts may initiate a change to a qₛ; that should be propagated to the diagram Q since some part of it has changed.
We implement the two directions asymmetrically. The "up" direction is implemented simply by subscribing every diagram-level tracker to each of its constituent object's trackers. That way any change to a constituent notifies its parent via the usual subscriber notification code. Other than the code to set up the subscriptions properly, there is no explicit code needed to handle the "up" notifications. See DiagramContext::SubscribeDiagramCompositeTrackersToChildrens() for the code that sets up these subscriptions. The following table shows the Diagram-specific notifications and subscriptions:
| Diagram tracker | Notifications sent ("down") | Subscribes to ("up") |
|---|---|---|
| time | subsystem time | — ¹ |
| accuracy | subsystem accuracy | — ¹ |
| q | subsystem q | subsystem q |
| v | subsystem v | subsystem v |
| z | subsystem z | subsystem z |
| xd | subsystem xd | subsystem xd |
| xa | subsystem xa | subsystem xa |
| pn | subsystem pn | subsystem pn |
| pa | subsystem pa | subsystem pa |
| xcdot | — | subsystem xcdot |
| pe | — | subsystem pe |
| ke | — | subsystem ke |
| pc | — | subsystem pc |
| pnc | — | subsystem pnc |
Notes
The "down" direction could have been handled via subscriptions also, at the cost of introducing cycles into the dependency DAG (the "change event" would serve to break those cycles during notification sweeps). Instead, the "down" direction is implemented via bespoke code for the Context modification methods that recursively visits each subcontext and executes the same modification and out of date notifications there. That is similar to the treatment of local composite trackers as discussed in Handling of composite trackers above.
Note that a lower-level subcontext may also have fixed input port values, and that a Diagram is completely unaware of any subsystem input ports whose values have been fixed locally. When a subcontext fixed input port value changes, all downstream computations are properly notified. For example, a subcontext time derivative cache entry might depend on the fixed input port. As long as the composite Diagram time derivatives cache entry has subscribed to its subsystems' time derivative cache entries, that change will also mark the Diagram time derivative out of date.
The figure below depicts the tracker subscriptions detailed in the above sections. The arrow direction reads as "subscribes to (up)", i.e., "depends on":
The logical cache entry object is split into two pieces to reflect the const and mutable aspects. Given a CacheIndex, either piece may be obtained very efficiently. The const part is a CacheEntry owned by the System, and consists of:
The mutable part is a CacheEntryValue and associated DependencyTracker, both owned by the Context. The CacheEntryValue is designed to optimize access efficiency. It contains:
When a prerequisite of a cache entry value changes, the associated DependencyTracker sets its CacheEntryValue's "out of date" boolean true. When a new value is computed and assigned the "out of date" boolean is cleared to false by the code that performed the assignment. For debugging and performance analysis, there is also a flag indicating whether caching has been disabled for this entry, in which case the value is considered in need of recomputation every time it is accessed. The out of date flag operates even when caching is disabled but is ignored in that case by Eval() methods. The sense of these flags is chosen so that only a single check that an int is zero is required to know that a value may be returned without computation.
To summarize, the Eval() method for a CacheEntry operates as follows:
The DependencyTracker is designed to optimize invalidation efficiency. It contains:
A prerequisite change to a particular value source works like this:
For efficiency, changes to multiple value sources can be grouped into the same change event. Also, DependencyTracker subscriber lists and cache entry references are just direct pointers (internal to the overall diagram Context) so no lookups are required. This is very fast but makes cloning a Context more difficult because the pointers must be fixed up to point to corresponding entities in the clone.
(Note that the "down" direction for Diagram notifications (as described above) currently uses bespoke recursive code to notify all the subsystems. It would likely be faster to use the subscription mechanism there also.)
It is important to emphasize that a Context never contains pointers to a particular System. Thus the allocator and calculator functors for a cache entry reside in the (sub)System, not in the (sub)Context. That implies that you cannot evaluate a cache entry without both a System and a Context. It also means you can use the same Context with different Systems, and that a Context could be serialized then deserialized to use later, provided that a compatible System is available.
Drake's System framework provides a careful separation between the persistent structure of a System and its ephemeral values (Context). The structure is represented in const objects derived from SystemBase, while the values are represented in mutable objects derived from ContextBase. Generally that means that what are logically single objects are split into two separate classes. Since users are intended to interact primarily with System objects, we use the logical names for the System half of the object, and more obscure names for the Context half that stores the runtime values. Here are some examples:
| Logical object | System-side class | Context-side class |
|---|---|---|
| System | System | Context |
| Output port | OutputPort | (cache entry) |
| Input port | InputPort | FixedInputPortValue |
| Cache entry | CacheEntry | CacheEntryValue |
| Dependency tracker | (ticket only) | DependencyTracker |
The System-side objects are used for declaring the computational structure of a System; the Context-side objects are used to maintain correct current values. For example, the necessary allocation and calculation methods for a cache entry are stored in the System-side CacheEntry object in the System, while the result of executing those methods is stored in the corresponding CacheEntryValue object in the Context.
Each port and each cache entry is assigned a unique DependencyTracker object. Output ports generally also have their own cache entries for storing their values; that results in two DependencyTrackers – the output port DependencyTracker lists its cache entry's DependencyTracker as a prerequisite. (TODO: In the initial implementation there will always be a cache entry assigned for leaf output ports, but this design is intended to allow output ports to forward from other sources without making unnecessary copies – an output port DependencyTracker is still needed in those cases even though there won't be an associated cache entry.)
The Calc() function and list of prerequisite supplied to the declare output ports APIs are used directly to construct the output port's cache entry.
The built-in computations like time derivatives, energy, and power are associated with bespoke "Calc" methods which need to have known dependency lists. Rather than add these with yet more System methods, we should consider changing the API to define them analogously to the OutputPort and CacheEntry declarations which accept Allocator() and Calculator() functors and a dependency list for the Calculator(). Currently they are just defaulting to "depends on everything".
See Drake issue #9205 on GitHub for a checklist of caching loose ends.